Sarracenia Status January 2018
Sarracenia is a small application iteratively developed by addressing one use case at a time, so development and deployment have been inextricably linked up to this point. That iterative process precipitated changes in the core of the application which have made it something of a moving target until now. In January 2018, the application has reached the point where all intended use cases are addressed by the application core. In the coming year, the emphasis will be on facilitating on-boarding, development of some derived services, and deploying the newly complete application more generally.
Comparison to 2015 Video
The November 2015 video ( Sarracenia in 10 Minutes ) outlined a vision. First phase of development work occurred in 2015 and early 2016, followed by important deployments later in 2016. This update, written in early 2018, explores progress made mostly in 2017.
Use cases mentioned in the video which were implemented:
Central meteorological pumping has made substantial progress in migrating to the new stack. This was the central initial use case that drove initial work. The transformation is not complete but is well in hand.
Redundant RADAR acquisition through two national hubs (spring 2016)
National Ninjo (main workstation for Forecasters) Dissemination (summer 2016)
Unified RADAR Processing (application to transform volume scans to products) data flows (through 2017)
Use cases in the video, but not yet realized:
End user usage. A few trials were completed in early in 2017 leading to some review, refactoring, and now retesting.
Data sets from sequencers have been waiting for end user use cases to be improved.
Reporting to sources who consumed their products. The feature is designed but further implementation, testing and careful deployment is needed.
Multi-pump routing by source-routing. Currently routing through multiple pumps is done by pump administrators, rather than end users. Without end-user on-boarding, routing by sources was a low priority.
The mesh interconnect model envisioned has not seen an appropriate use case.
Unanticipated use cases implemented:
GTS data exchange: CMC <-> NWS. NWS requested a change in connectivity in December 2015.
HPC mirroring (to be completed in Spring 2018).
Legacy Application 7-way replication (for SPCs) implemented last year.
GOES-R acquisition (live as of January 2018).
Details to follow.
Central Data Flows
The slide below corresponds to deployed daily data flows in support of Environment Canada, mostly for operational weather forecasting, in place since January 2018.
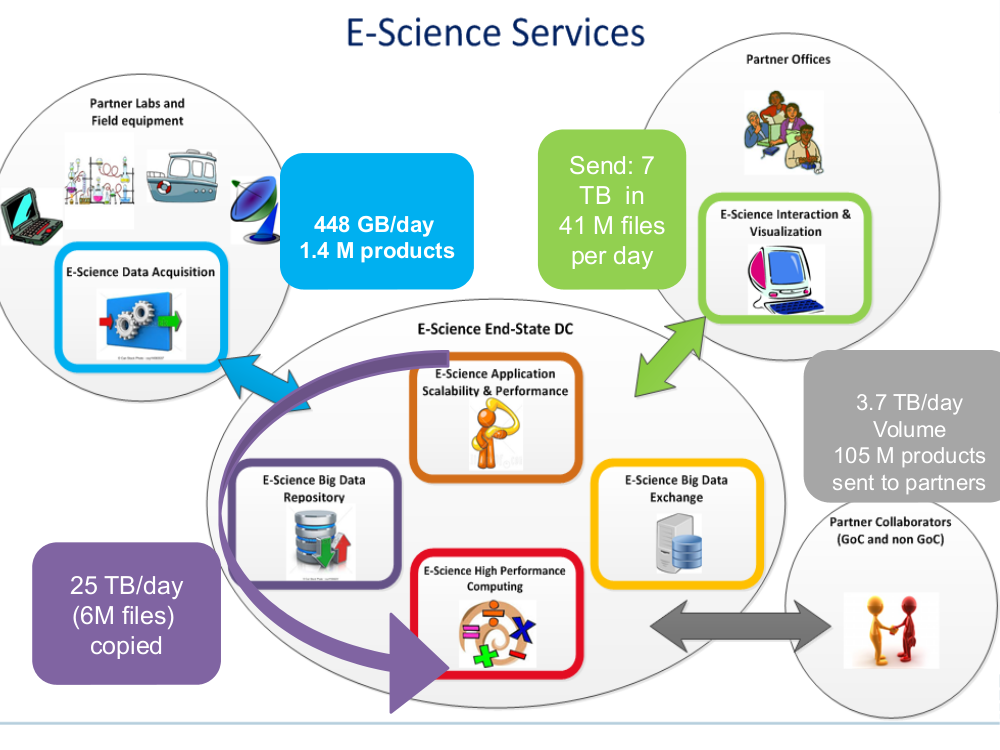
Sarracenia is being used operationally to acquire about four terabytes of observations from automated weather observing systems, weather RADARS which deliver data directly to our hubs, and international peer operated public file services, which provide satellite imagery and numerical products from other national weather centres.
Within the main high performance computing (HPC) data centre, there are two supercomputers, two site stores, and two pre- and post-processing clusters. Should a component in one chain fail, the other can take over. The input data is sent to a primary chain, and then processing on that chain is mirrored, using sarracenia to copy the data to the other chain. That’s about 16 of the 25 terabytes of the data centre traffic in this diagram.
A distillation of the data acquired, and the analysis and forecasts done in HPC, is the 7 terabytes at the top right, that is sent to the seven regional Storm Prediction Centres (SPCs).
The products of the SPCs and the central HPC are then shared with the public and partners in industry, academia and other governments.
Weather Application Flows
FIXME: picture?
There is a number (perhaps a dozen?) of older applications (the most prominent ones being BULLPREP and Scribe) used for decades in the Storm Prediction Centres to create forecast and warning products. These applications are based on a file tree that they read and write. Formerly, each application had its own backup strategy with one of the six other offices and bi-lateral arrangements were made to copy specific data among the trees.
In January 2017, complete 7-way replication of the state file trees of the applications was implemented so that all offices have copies of files in real-time. This is accomplished using Sarracenia through the eastern hub. Any forecast office can now take over work of any product for any other, with no specific application work needed at all.
GOES-R Acquisition
Acquisition of simulated and real GOES-R products from NOAA’s PDA, as well as via local downlinks at one location (eventually to become two) was entirely mediated by Sarracenia. The operational deployment of GOES-R happened in the first week of January, 2018.
HPC Acquisition Feeds
FIXME: picture?
The supercomputing environment was entirely replaced in 2017. As part of that, the client Environmental Data acquisition suite (ADE in French) was refactored to work with much higher performance than previously, and to accept Sarracenia feeds directly, rather than accepting feeds from previous generation pump (Sundew). The volume and speed of data acquisition has been substantially improved as a result.
RADAR Data Flows
If we begin with RADAR data acquisition as an example, individual RADAR systems use FTP and/or SFTP to send files to eastern and western communications hubs. Those hubs run the directory watching component (sr_watch) and determine checksums for the volume scans as they arrive. The Unified RADAR Processing (URP) systems sr_subscribes to a hub, listening for new volume scans, and downloads new data as soon as they are posted. URP systems then derive new products and advertise them to the local hub using the sr_post component. In time, we hope to have a second URP fully at the western hub.
In regional offices, the NinJo visualization servers download volume scans and processed data from URP using identical subscriptions, pulling the data from whichever national hub makes the data available first. The failure of a national hub is transparent for RADAR data in that the volume scans will be downloaded from the other hub, and the other URP processor will produce the products needed.
Each site has multiple Ninjo servers. We use http-based file servers, or web accessible folders to serve data. This allows easy integration of web-proxy caches, which means that only the first Ninjo server to request data will download from the national hub. Other Ninjo servers will get their data from the local proxy cache. The use of Sarracenia for notifications when new products are available is completely independent of the method used to serve and download data. Data servers can be implemented with a wide variety of tools and very little integration is needed.
HPC Mirroring
All through 2017, work was proceeding to implement high speed mirroring between the supercomputer site stores to permit failover. That work is now in a final deployment phase, and should be in operations by spring 2018. For more details see: HPC Mirroring Use Case
Application Changes in 2017
Development of Sarracenia had been exploratory over a number of years. The use cases initially attacked were those with a high degree of expert involvement. It proceeded following the minimum viable product (MVP) model for each use case, acquiring features to deal with next use case prior to deployment. In 2016, national deployment of NinJo and the Weather.
Expanded use cases explored:
Mirroring: Prior to this use case, Sarracenia was used for raw data dissemination without regard for permissions, ownership, symbolic links, etc… For the mirroring use case, exact metadata replication was a surprisingly complex requirement.
C-implementation: In exploring large scale mirroring, it became obvious that for sufficiently large trees (27 Million files), the only practical method available was the use of a C shim library. Having all user codes invoke a Python3 script is complete nonsense in an HPC environment, so it was necessary to implement a C version of Sarracenia posting code for use by the shim library. Once the C implementation was begun, it was only a little additional work to implement a C version of sr_watch (called sr_cpost) which was much more memory and CPU efficient than the Python original.
Node.js implementation: A client of the public datamart decided to implement enough of Sarracenia to download warnings in real-time.
The application was refactored to maximize consistency through code reuse, reducing about 20% of the code size at one point. The code returned to the initial size when new features were added, but it remains quite compact at less than 20 kloc.
End-user usage: All of the deployments thus far are implemented by analysts with a deep understanding of Sarracenia, and extensive support and background. This year, we went through several iterations of having users deploy their flows, collecting feedback and then making it easier for end users at the next iteration. Many of these changes were breaking changes, in that options and ways or working were still prototypes and required revision.
Changes to support end user usage:
Exchanges were an administrator-defined resource. Permission model changed such that users can now declare exchanges.
Previously, one had to look on web sites to find examples. Now, the list command displays many examples included with the package.
It was hard to find where to put settings files. The list/add/remove/edit commands simplify that.
In each plugin entry point, one had to modify different instance variables, was refactored for consistency across all of them (on_msg, on_file, on_part, on_post, do_download, do_send, etc…).
Partitioning specifications were arcane and were replaced with the blocksize option, with only three possibilities: 0, 1, many.
Routing across multiple pumps was arcane. The original algorithm was replaced by a simpler one with some smarter defaults. Users can now usually ignore it.
A much more elegant plugin interface is available to have multiple routines that work together, specified in a single plugin.
Previously, only advertised on web servers relative to the root URL. Now, non-root base URL support was added.
The only major operational feature introduced in 2017 was save/restore/retry: if a destination has a problem, there is substantial risk of overloading AMQP brokers by letting queues of products to transfer grow into millions of entries. Functionality to efficiently (in parallel) offload broker queues to local disk was implemented to address this. At first, recovery needed to be manually triggered (restore) but by the end of the year, an automated recovery (retry) mechanism was working its way to deployment, which will reduce requirements for oversight and intervention in operations.
Coming in 2018
As of release 2.18.01a5, all of the use cases targeted have been explored and reasonable solutions are available, so there should be no further changes to the existing configuration language or options. No changes to existing configuration settings are planned. Some minor additions may still occur, but not at the cost of breaking any existing configurations. The core application is now complete.
Expect in early 2018 for the last alpha package release and for subsequent work to be on a beta version with a target of a much more long-lived stable version some time in 2018.
HPC mirroring use case deployment will be completed.
The Permanent File Depot (PFD) use case will be deployed. Currently, this is used to cover a short time horizon. One can extend it arbitrarily into the past by persisting the time-based tree to nearline storage. In development since 2016, gradually progressing.
Improve deployment consistency: The changes in 2017 were confusing for the expert analysts, as significant changes in details occurred across versions. Different deployments currently use different operational versions, and most issues arising in operations are addressed by the existing code, but are not yet deployed to that use case. In 2018, we will revisit early deployments to bring them up to date.
Continued improvement in pre-deployment testing.
The Sarrasemina indexing tool, which facilitates finding feeds, to be deployed to assist onboarding.
Improved onboarding documentation. Reference materials are thorough, but introductory quick-start and gateway oriented materials need work. French translations are also needed.
Reporting: While reporting was baked in from the start, it proved to be very expensive, and so deployments to date have omitted it. Now that deployment loads are quieting down, this year should allow us to add real-time report routing to deployed configurations. There is no functionality to develop, as everything is already in the application, but mostly not used. Use may uncover additional issues.
Pluggable checksum algorithms. Currently checksum algorithms are baked into the implementations. There is a need to support plugins to support user-defined checksum algorithms (expected in 2.18.02a1).
Continued progressive replacement of legacy application configurations (RPDS, Sundew).
Continued adaptation of applications to Sarracenia (DMS, GOES-R).
Deployment of additional instances: flux.weather.gc.ca, hpfx.collab.science.gc.ca, etc…
Continued work on the corporate approval and funding of the western hub (aka. Project Alta).