Status: Approved-Draft1-20150608
Idée de Base
MetPX-Sarracenia est un moteur de duplication ou de distribution de données qui exploite des technologies standard existantes (serveurs sftp et Web et courtiers AMQP) pour obtenir des livraison de messages en temps réel et une transparence de bout en bout dans les transferts de fichiers. Alors qu’à Sundew, chaque pump est une configuration autonome qui transforme les données de manière complexe, dans sarracenia, les sources de données établissent une structure qui est réalisée à travers n’importe quel nombre de pompes intermédiaires jusqu’à ce qu’elles arrivent chez un client. Le consommateur peut fournir un accusé de réception explicite qui se propage à travers le réseau jusqu’a une source.
Alors que le pompage traditionnel des fichiers est une affaire de point à point où la connaissance n’est que entre chaque segment, dans Sarracenia, l’information circule de bout en bout dans les deux sens. À la base, sarracenia expose un arbre de dossiers accessibles sur le Web (WAF), en utilisant tout serveur HTTP standard (testé avec apache). Les applications météo sont douces en temps réel, où les données doivent être livrées le plus rapidement possible au tronçon suivant, et les minutes, peut-être les secondes, comptent. Les technologies standard de web push, ATOM, RSS, etc… sont en fait des technologies d’interrogation qui, lorsqu’elles sont utilisées dans des applications à faible latence, consomment beaucoup de bande passante et de surcharge. Pour exactement ces raisons, ces normes stipulent un intervalle d’interrogation de minimum cinq minutes. La mise en fil d’attente avancée des messages (AMQP) apporte de véritables notifications push et rend l’envoi en temps réel beaucoup plus efficace.
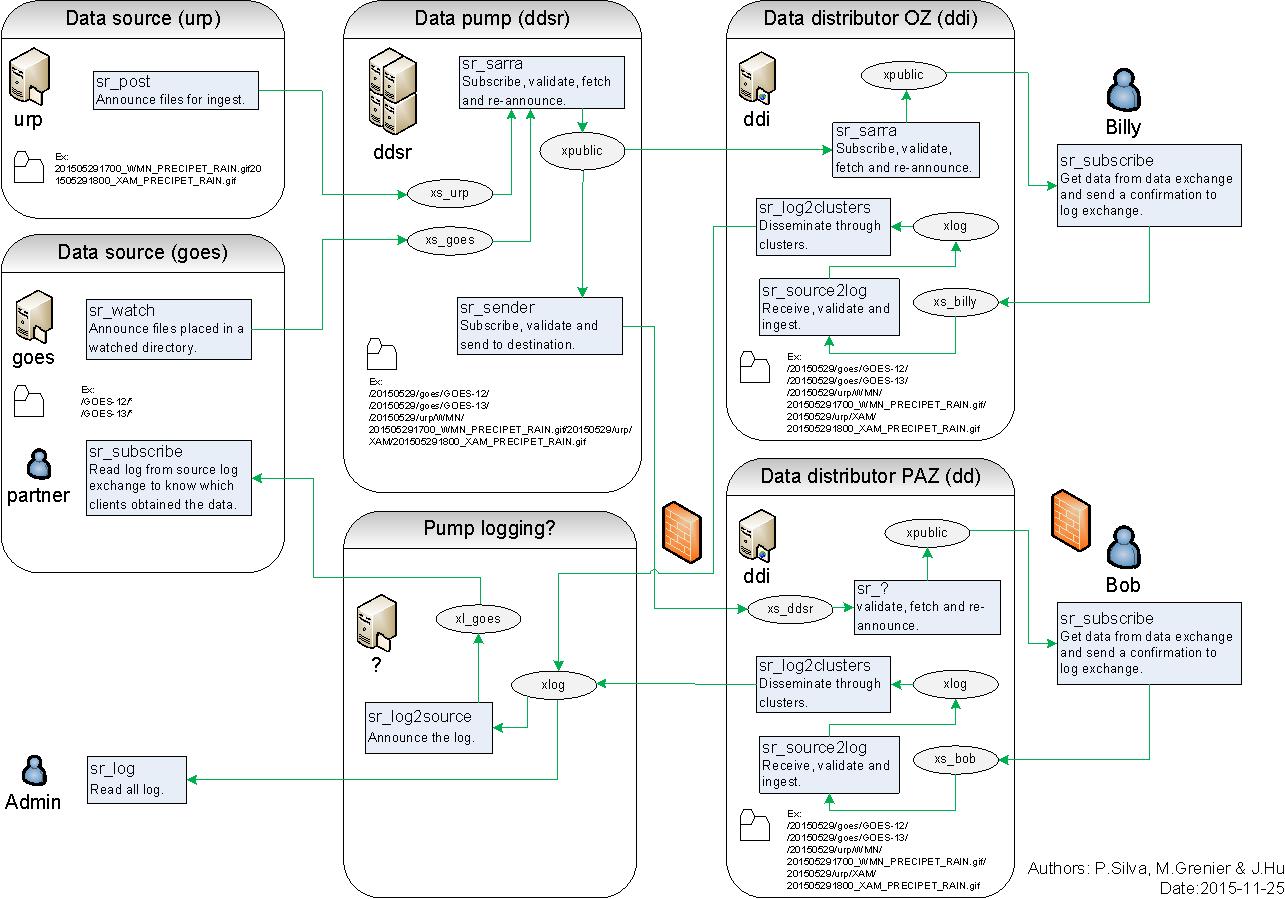
Les sources de données annoncent leurs produits, les systèmes de pompage extraient les données sur leurs arbres WAF, puis annoncent leurs arbres pour les clients en aval. Lorsque les clients téléchargent des données, ils peuvent écrire un message de rapport (report) sur le serveur. Les serveurs sont configurés pour transférer ces rapports du client via les serveurs intermédiaires vers la source. La Source peut voir l’intégralité du chemin emprunté par les données pour accéder à chaque client. Avec les applications de pompage traditionnelles, les sources ne voient que ce qu’elles ont livré au premier saut d’une chaîne. Au-delà de ce premier saut, le routage est opaque et le traçage du chemin des données nécessite l’assistance des administrateurs de chaque système intervenant. Avec l’envoi de fichiers journaux de Sarracenia, le réseau de pompage est totalement transparent aux sources. Avec des journaux de bout en bout, des diagnostics sont grandement simplifiés pour tout le monde.
Pour les fichiers volumineux / hautes performances, les fichiers sont segmentés lors de l’ingestion s’ils sont suffisamment grand pour que cela en vaille la peine. Chaque fichier peut traverser le réseau de pompes indépendamment, et le remontage n’est nécessaire qu’aux points d’extrémité. Un fichier de taille suffisante annoncera sa disponibilité de plusieurs segments pour le transfert, et plusieurs threads ou de nœuds de transfert ramassera des segments et les transférera. Plus il y a de segments disponibles, plus le parallélisme du transfert. Sarracenia gère le parallélisme et l’utilisation du réseau sans intervention explicite de l’utilisateur. Comme les pompes intermédiaires ne stockent pas et ne transferent pas de fichiers entiers, la taille maximale du fichier pouvant traverser le réseau est maximisée.
Ces concepts ci-dessous ne sont pas en ordre (encore?) peut-être que nous le ferons plus tard. Pas sûr des priorités, juste le nombre pour pouvoir s’y référer. Ils sont destinés à guider (réfléchir?) des décisions de conception / mise en œuvre:
Pour chaque objectif/considération/conseil ci-dessous, voyez s’ils ont du sens, et semblent utiles. Nous devrions nous débarrasser de tout ce qui n’est pas utile.
La pompe est, ou n’importe quel nombre de pompes sont, transparentes. En d’autres termes: La source est en charge des données qu’elles fournissent.
La source détermine la distribution (étendue et autorisations) La source peut obtenir n’importe quelle information sur elle-même:
- quand le statut change: start,stop,drop. - quand les messages de notifications sont acceptés. - lorsque les données sont extraites par un consommateur (scope layer ou end point.)
Les courtiers AMQP ne transfèrent aucune donnée d’utilisateur, mais uniquement des métadonnées.
raisonnement: doivent garder les messages de notification petits afin que le taux de transfert soit élevé. De grands messages de notification gommageront les travaux. Les autorisations deviennent également intéressantes. se retrouvent avec un seuil de “taille maximale” et mettent en œuvre deux méthodes pour tout.
Les modifications de configuration doivent se propager et ne peuvent pas être uniques à un hôte vous ne devriez pas avoir à faire dsh, ou px-push. Ce genre de gestion est intégré. le bus de messages est là pour cela. peut utiliser ‘scope’ pour que les commandes se propagent à travers plusieurs clusters.
Le rapport est une donnée.
Il ne suffit pas que justice soit faite. Justice doit être perçue comme étant faite.
Il ne suffit pas que les données soient fournies. Cette livraison doit être enregistrée, et ce rapport doit être renvoyé à la source. Alors que nous voulons fournir suffisamment d’informations pour les sources de données, nous ne voulons pas noyer le réseau dans les métadonnées. Les journaux des composants locaux auront beaucoup plus d’informations, les messages de rapport traversant le réseau jusqu’à la source sont des “dispositions finales” chaque fois qu’une opération est terminée ou finalement abandonnée.
Il s’agit d’un outil de distribution de données, pas d’un réplicateur d’arborescence de fichiers.
nous n’avons pas besoin de savoir ce que linux uid/gid possédait à l’origine.
nous ne nous soucions pas de savoir quand il a été modifié.
nous ne nous soucions pas de ses bits d’autorisation d’origine.
nous ne nous soucions pas du ACL qu’il a (ils ne sont pas pertinents sur la destination.)
nous ne nous soucions pas des attributs étendus. (portabilité, win,mac,lin,netapp?)
encore douteux à propos de celui-ci. Est-ce que cela aide?
Ne pas s’inquiéter de la performance dans la phase 1 - les performances sont rendues possibles par l’évolutivité de la conception
-- la segmentation/réassemblage fournit le multi-threading. - la segmentation signifie un transfert de fichiers plus volumineux avec un plus grand parallélisme. ajoute plusieurs flux lorsque cela en vaut la peine, utilise un seul flux quand cela a du sens. -- la validation permet de limiter la bande passante de la source.
il faut d’abord prouver que toutes les pièces mobiles fonctionnent ensemble.
beaucoup plus tard, on peut revenir pour voir comment faire en sorte que chaque moteur de transfert aille plus vite.
Ce n’est pas une application web, ce n’est pas un serveur FTP.
Cette application utilise HTTP comme l’un des protocoles de transport, c’est tout. Il n’essaie pas d’être un site Web, pas plus qu’il n’essaie d’être un serveur sftp.
Une gestion commune n’est pas nécessaire, il suffit de passer des journaux.
Différents groupes peuvent gérer différentes pompes. lorsque nous interconnectons des pompes, elles deviennent une source pour nous. les messages de rapport sont routés vers les sources de données, de sorte qu’elles obtiennent nos journaux sur leur données. (la sécurité peut avoir quelque chose à dire à ce sujet.)
Il doit fonctionner n’importe où. ubuntu,centos – primaire. mais windows aussi.
Nous essayons de faire une pompe que d’autres peuvent facilement adopter. Cela signifie qu’ils peuvent installer et démarrer.
- Il doit être facile à configurer, à la fois pour le client et le serveur.
(cet aspect est traité dans l’emballage)
l’application n’a pas besoin de rechercher une fiabilité absolue.
La défaillance de nœud est rare dans un environnement de centre de données. Bien travailler dans le cas normal est la priorité. s’il se brise, l’information n’est jamais perdue. Dans le pire des cas, il suffit de re-poster, et le système renverra les pièces manquantes à travers les nœuds qui restent.
Il peut y avoir des diagnostics pour déterminer quels fichiers sont “en vol” lorsqu’un nœud donné tombe en panne (minuteries deadman). Mais pas sûr que des acks multiples avec des garanties en cas de défaillance du nœud sont nécessaires. aller plus vite et être plus simple est probablement plus fiable dans la pratique.
il ne s’agit pas d’une base de données, mais d’un moteur de transfert.
Les bulletins deviennent moins courants, les fichiers sont plus volumineux… Pas de fichier trop volumineux.
les anciennes applications sont utilisées pour de minuscules fichiers (des millions d’entre eux) dans EC / MSC. mais même dans EC, les fichiers deviennent de plus en plus volumineux et vont probablement beaucoup croître. Les données des capteurs satellitaires sont maintenant très critiques, et elles sont beaucoup plus volumineuses. Un avertissement météorologique traditionnel au format WMO était limité à 15 Koctets (limité par des données internes). à 32 Ko maintenant) et ces tailles étaient rarement atteintes. C’était plus comme 7-12K. un avertissement météorologique XML moderne moyen (CAP) est de 60K donc, une augmentation de cinq à huit fois. WMO a depuis relevé la limite à 500 000 octets pour les messages WMO-GTS. et d’autres mécanismes, tels que FTP, n’ont pas de limite fixe.
D’autres domaines scientifiques utilisent des fichiers très volumineux (mesurés en téraoctets). pour les faire circuler à travers les pompes. Cela vaut la peine de penser à transporter d’énormes fichiers.
Le fonctionnement normal ne devrait pas nécessiter de connaissances en programmation.
La configuration et le codage sont des activités distinctes. Il ne faut pas avoir à modifier les scripts pour configurer les éléments standard de l’application. Le logiciel peut être beaucoup plus simple s’il laisse simplement toutes les fonctionnalités implémentées sous forme de scripts de plug-in. En laissant les détails locaux pour les scripts. Mais la plupart des gens ne pourront pas l’utiliser.
Au moins besoin de fournir toutes les fonctionnalités de base via CLI. Les fichiers de configuration font une partie intégrante de l’interface de ligne de commande, c’est pourquoi nous essayons de choisir avec soin là aussi. Pour les programmeurs, la différence entre script et la config est subtile, ce n’est pas le cas pour la plupart des autres.
L’écriture de scripts est seulement requise pour étendre les fonctionnalités au-delà de ce qui est standard, pour offrir plus de souplesse. Si la flexibilité s’avère généralement utile au fil du temps, alors, cela devrait être sorti des scripts et dans le domaine de la configuration.